Using the BLIP-2 Model for Image Captioning
2024-03-05Overview
In the previous post we looked at the BLIP model for image captioning. The same group of researchers from Salesforce developed a more advanced version of the BLIP model, called BLIP-2. In this post we will look at the BLIP-2 model and how we can use it for image captioning tasks.
The BLIP-2 paper proposes a generic and efficient pre-training strategy that bootstraps vision-language pre-training from off-the-shelf frozen pre-trained image encoders and frozen large language models. BLIP-2 bridges the modality gap with a lightweight Querying Transformer, which is pre-trained in two stages. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen language model. BLIP-2 achieves state-of-the-art performance on various vision-language tasks, despite having significantly fewer trainable parameters than existing methods.
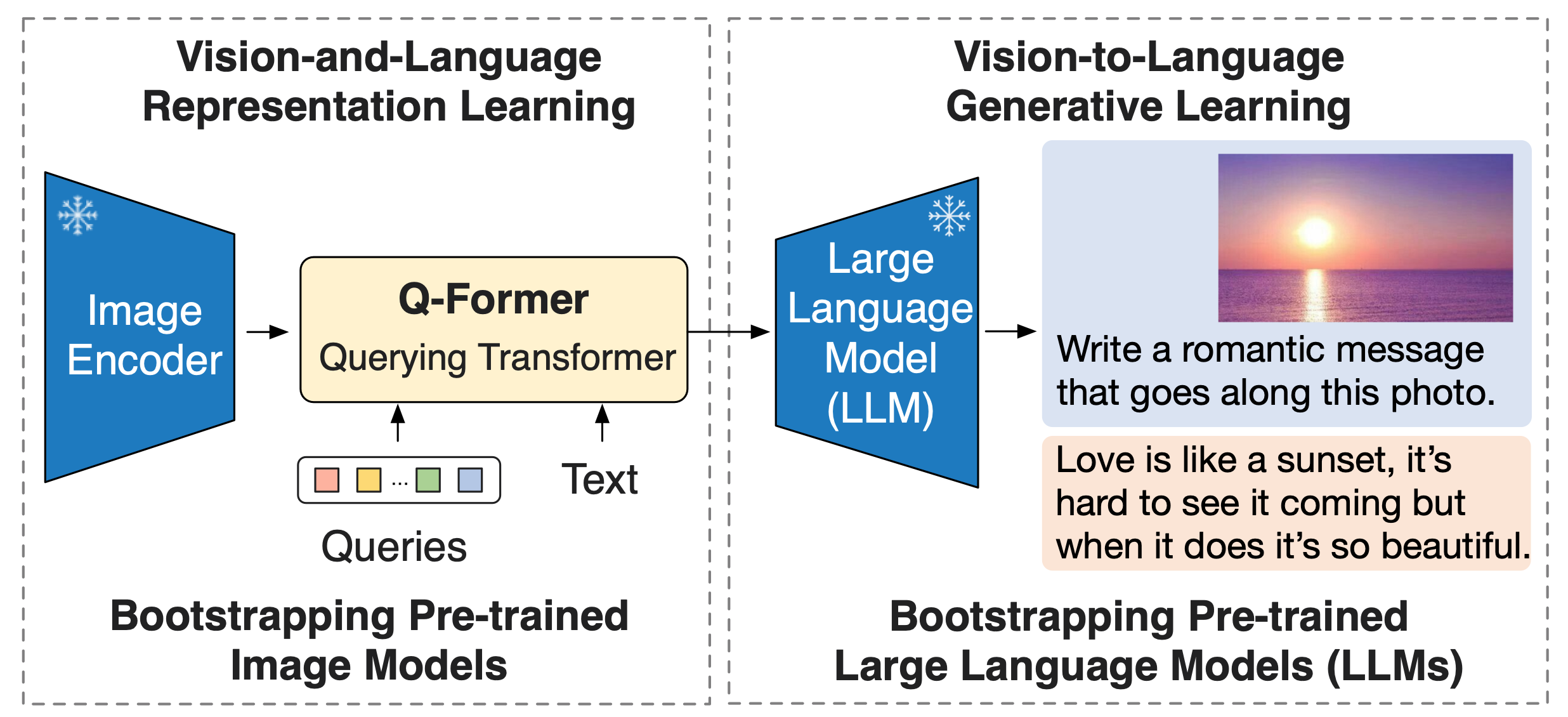
Image captioning with BLIP-2
Step 1: Install the lavis library
The lavis library provides a simple API for loading pre-trained models and processing images
and text. The lavis library can be installed using pip:
$ pip install salesforce-lavis
Step 2: Generate image captions
The code snippet below demonstrates how to use the BLIP-2 model for image captioning.
import torch
import requests
from PIL import Image
img_url = 'https://i.pinimg.com/564x/26/c7/35/26c7355fe46f62d84579857c6f8c4ea5.jpg'
device = torch.device("cuda") if torch.cuda.is_available() else "cpu"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
import torch
from lavis.models import load_model_and_preprocess
model, vis_processors, _ = load_model_and_preprocess(
name="blip2_t5",
model_type="caption_coco_flant5xl",
is_eval=True,
device=device
)
image = vis_processors["eval"](raw_image).unsqueeze(0).to(device)
# generate caption using beam search
model.generate({"image": image})
# generate caption using necleus sampling
# due to the non-determinstic nature of necleus sampling, you may get different captions.
model.generate({"image": image}, use_nucleus_sampling=True, num_captions=3)
CaptionCraft support of BLIP-2
CaptionCraft provides an easy-to-integrate API for image captioning using the BLIP-2 model. You can try it out for free at https://rapidapi.com/fantascatllc/api/image-caption-generator2.